![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
This chapter covers the following topics:
The Process Manager works closely with the Microkernel to provide essential operating system services. Although it shares the same address space as the Microkernel (and is the only process to do so), the Process Manager runs as a true process. As such, it is scheduled to run by the Microkernel like all other processes and it uses the Microkernel's message-passing primitives to communicate with other processes in the system.
The Process Manager is responsible for creating new processes in the system and managing the most fundamental resources associated with a process. These services are all provided via messages. For example, if a running process wants to create a new process, it does so by sending a message containing the details of the new process to be created. Note that since messages are network-wide, you can easily create a process on another node by sending the process-creation message to the Process Manager on that node.
QNX supports three process-creation primitives:
Both fork() and exec() are defined by POSIX, while the implementation of spawn() is unique to QNX.
The fork() primitive creates a new process that is an exact image of the calling process. The new process shares the same code as the calling process and inherits a copy of all of the calling process's data.
The exec() primitive replaces the calling process image with a new process image. There's no return from a successful exec(), because the new process image overlays the calling process image. It's common practice in POSIX systems to create a new process -- without removing the calling process -- by first calling fork(), and then having the child of the fork() call exec().
The spawn() primitive creates a new process as a child of the calling process. It can avoid the need to fork() and exec(), resulting in a faster and more efficient means for creating new processes. Unlike fork() and exec(), which by their very nature operate on the same node as the calling process, the spawn() primitive can create processes on any node in the network.
When a process is created by one of the three primitives just described, it inherits much of its environment from its parent. This is summarized in the following table:
| Item inherited | fork() | exec() | spawn() |
|---|---|---|---|
| process ID | no | yes | no |
| open files | yes | optional* | optional |
| file locks | no | yes | no |
| pending signals | no | yes | no |
| signal mask | yes | optional | optional |
| ignored signals | yes | optional | optional |
| signal handlers | yes | no | no |
| environment variables | yes | optional | optional |
| session ID | yes | yes | optional |
| process group | yes | yes | optional |
| real UID, GID | yes | yes | yes |
| effective UID, GID | yes | optional | optional |
| current working directory | yes | optional | optional |
| file creation mask | yes | yes | yes |
| priority | yes | optional | optional |
| scheduler policy | yes | optional | optional |
| virtual circuits | depends** | yes | depends** |
| symbolic names | no | no | no |
| realtime timers | no | no | no |
*optional: the caller may select either yes or no, as needed.
**depends: any virtual circuits that are needed to maintain something else (e.g. an open file) are inherited.
A process goes through four phases:
Creating a process consists of allocating a process ID for the new process and setting up the information that defines the environment of the new process. Most of this information is inherited from the parent of the new process (see the previous section on "Process inheritance").
The loading of process images is done by a loader thread. The loader code resides in the Process Manager, but the thread runs under the process ID of the new process. This lets the Process Manager handle other requests while loading programs.
Once the program code has been loaded, the process is ready for execution; it begins to compete with other processes for CPU resources. Note that all processes run concurrently with their parents. In addition, the death of a parent process does not automatically cause the death of its child processes.
A process is terminated in either of two ways:
Termination involves two stages:
If the parent process hasn't issued a wait() or waitpid() call, the child process becomes a "zombie" process and won't terminate until the parent process issues a wait() or terminates. (If you don't want a process to wait on the death of children, you should either set the _SPAWN_NOZOMBIE flag with qnx_spawn() or set the action for SIGCHLD to be SIG_IGN via signal(). This way, children won't become zombies when they die.)
A parent process can wait() on the death of a child spawned on a remote node. If the parent of a zombie process terminates, the zombie is released.
If a process is terminated by the delivery of a termination signal and the dumper utility is running, a memory-image dump is generated. You can examine this dump with the symbolic debugger.
A process is always in one of the following states:
 |
For more information on blocked states, see Chapter 2, The Microkernel. |
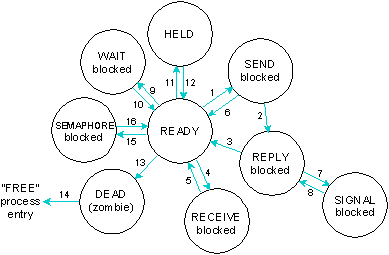
Possible process states in a QNX system.
The transactions depicted in the previous diagram are as follows:
To determine the state of an individual process from within the Shell, use the ps and sin utilities (from within applications, use the qnx_psinfo() function).
To determine the state of the operating system as a whole from within the Shell, use the sin utility (from within applications, use the qnx_osinfo() function).
The ps utility is defined by POSIX; its use in command scripts may be portable. The sin utility, on the other hand, is unique to QNX; it gives you helpful QNX-specific information that you can't get from the ps utility.
QNX encourages the development of applications that are split up into cooperating processes. An application that exists as a team of cooperating processes exhibits greater concurrency and can be network-distributed for greater performance.
Splitting up applications into cooperating processes requires special considerations, however. If cooperating processes are to communicate reliably with each other, they must be able to determine each other's process ID. For example, let's say you have a database server process that provides services to an arbitrary number of clients. The clients start and stop at any time, but the server always remains available. How do client processes discover the process ID of the database server so they can send messages to it?
In QNX, the solution is to let processes give themselves a symbolic name. In the context of a single node, processes can register this name with the Process Manager on the node where they're running. Other processes can then ask the Process Manager for the process ID associated with that name.
The situation becomes more complex in a network environment where a server may need to service clients from several nodes across a network. QNX accordingly provides the ability to support both global names and local names. Global names are known across the network, whereas local names are known only on the node where they're registered. Global names start with a slash (/). For example:
| qnx/fsys | local name |
| company/xyz | local name |
| /company/xyz | global name |
|
We recommend that you prefix all your names with your company name to reduce name conflicts among vendors. |
In order for global names to be used, a process known as a process name locator (i.e. the nameloc utility) must be running on at least one node of a network. This process maintains a record of all global names that have been registered.
Up to ten process name locators may be active on a network at a particular time. Each maintains an identical copy of all active global names. This redundancy ensures that a network can continue to function properly even if one or more nodes supporting process name location fail simultaneously.
To attach a name, a server process uses the qnx_name_attach() function. To locate a process by name, a client process uses the qnx_name_locate() function.
In QNX, time management is based on a system timer maintained by the operating system. The timer contains the current Coordinated Universal Time (UTC) relative to 0 hours, 0 minutes, 0 seconds, January 1, 1970. To establish local time, time management functions use the TZ environment variable (which is described in the Basic Installation chapter of the Installation & Configuration guide).
Shell scripts and processes can pause for a specific number of seconds, using a simple timing facility. For Shell scripts, this facility is provided by the sleep utility; for processes, it's provided by the sleep() function. You can also use the delay() function, which takes a time interval specified in milliseconds.
A process can also create timers, arm them with a time interval, and remove timers. These advanced timing facilities are based on the POSIX Std 1003.1b specification.
A process can create one or more timers. These timers can be any mix of supported timer types, subject to a configurable limit on the total number of timers supported by the operating system (see Proc32 in the Utilities Reference). To create timers, you use the timer_create() function.
You can arm timers with the following time intervals:
You can also have a timer go off repeatedly at a specified interval. For example, let's say you have a timer armed to go off at 9 am tomorrow morning. You can specify that it should also go off every five minutes thereafter.
You can also set a new time interval on an existing timer. The effect of the new time interval depends on the interval type:
| To arm timers with: | Use this function: |
|---|---|
| an absolute or relative time interval | timer_settime() |
To remove timers, you use the timer_delete() function.
You can set the resolution of timers by using the ticksize utility or the qnx_ticksize() function. You can adjust the resolution from 500 microseconds to 50 milliseconds.
To inspect the interval outstanding on a timer, or to check if the timer has been removed, you use the timer_gettime() function.
Interrupt handlers service the computer's hardware interrupt system -- they react to hardware interrupts and manage the low-level transfer of data between the computer and external devices.
Interrupt handlers are physically packaged as part of a standard QNX process (e.g. a driver), but they always run asynchronously to the process they're associated with.
An interrupt handler:
Several processes may attach to the same interrupt (if supported by the hardware). When a physical interrupt occurs, each interrupt handler in turn will be given control. No assumptions should be made about the order in which interrupt handlers sharing an interrupt are invoked.
| If you want to: | Use this function: |
|---|---|
| Establish a hardware interrupt | qnx_hint_attach() |
| Remove a hardware interrupt | qnx_hint_detach() |
You can attach an interrupt handler directly to the system timer so that the handler will be invoked on each timer interrupt. To set the period, you can use the ticksize utility.
You can also attach to a scaled timer interrupt that will activate every 50 milliseconds, regardless of the tick size. These timers offer a lower-level alternative to the POSIX 1003.4 timers.
|
|
|
|